
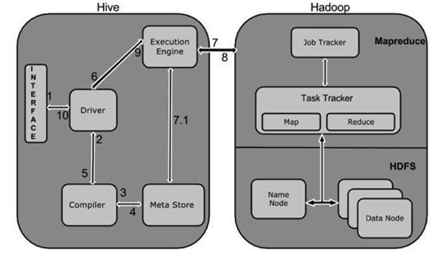
Alur kerja antara Hive dan Hadoop ditunjukkan dalam diagram di bawah ini, dijelaskan dengan baik oleh ahli tugas data besar kami, bantuan tugas.

Tabel terlampir mencirikan bagaimana Hive bekerja sama dengan sistem Hadoop:
Langkah No.Operasi Eksekusi query Antarmuka Hive, seperti Command-Line atau Web UI, mengirimkan pertanyaan ke Driver (driver kumpulan data apa pun, seperti JDBC, ODBC, dan sebagainya) untuk dieksekusi di layanan bantuan penugasan Hadoop oleh Big ahli data. Ambil
driver kekuatan pendorong Rencanakan bantuan kompiler kueri analisis kueri untuk menguji sintaks dan paket pertanyaan kesepakatan atau permintaan permintaan Dapatkan Metadata Metastore menerima permintaan metadata dari kompiler (basis informasi apa pun). Submit Metadata Metastore mengirimkan metadata kembali ke compiler. Kirim Paket
Kompiler melihat kebutuhan dan mengirim ulang asosiasi ke kekuatan motif. sampai di sini, penguraian dan urutan kueri selesai. Rencana Eksekusi Pengemudi mengirimkan rencana eksekusi ke mesin eksekusi. Menjalankan Pekerjaan Secara internal, proses menjalankan pekerjaan disebut pekerjaan MapReduce. Pekerjaan dikirimkan ke JobTracker di node Nama dan ditugaskan ke TaskTracker di node Data saat runtime. Kueri di sini menjalankan tugas MapReduce. Dapatkan Hasil Motor eksekusi mendapatkan hasil dari hub Data. Kirim Hasil Temuan dikirim ke Hive Interfaces melalui driver.
1. Sistem Distribusi File Hadoop (HDFS)
1.1 Pendahuluan
Ukuran data dengan cepat melebihi batas penyimpanan mesin saat kecepatan data meningkat. Data dapat disimpan di jaringan mesin sebagai solusi. Sistem file terdistribusi adalah nama dari jenis sistem file ini. Data disimpan di jaringan saat bekerja dan mengambil layanan bantuan penugasan Hadoop, memperkenalkan semua kesulitan jaringan. Di sinilah Hadoop masuk. Ini memiliki salah satu sistem file paling stabil di luar sana. HDFS (Hadoop Distributed File System) adalah sistem file tunggal yang menyimpan file yang sangat besar dan memungkinkan akses data online melalui perangkat keras yang mendasarinya. Mari kita lihat istilah lebih detail:
Dokumen yang sangat besar: Kita berbicara tentang data yang diukur dalam petabyte (1000 TB). Pola Akses Data Streaming: HDFS dibuat berdasarkan prinsip tulis sekali baca. Ketika sebagian besar dari kumpulan data dibuat, mereka mungkin disiapkan berkali-kali. Perangkat keras yang masuk akal dan tersedia secara efektif disebut sebagai perlengkapan gudang. Ini adalah salah satu fitur yang membedakan HDFS dari sistem file lainnya.
menyimpan statistik dalam HDFS: sekarang memungkinkan untuk melihat bagaimana informasi disimpan secara terdistribusi.

kita dapat mengandalkan dokumen 100TB yang disematkan, kemudian, pada saat itu, master node(namenode) akan mulai dengan mengisolasi file ke dalam kotak 10TB (panjang default adalah 128 MB di Hadoop 2. x atau lebih besar). Kemudian, pada saat itu, kotak-kotak itu ditempatkan di seluruh node data yang berbeda (slave node). Datanodes (slave node) mereplikasi kotak di antara mereka sendiri dan fakta tentang blok apa yang mereka buat dikirim dari ahli. Faktor replikasi default adalah 3 strategi untuk setiap kotak 3 salinan dibuat (menghitung sendiri). Dalam miliknya. web site.xml kita dapat menambah atau mengurangi aspek replikasi yaitu kita dapat menyesuaikan pengaturannya di sini saat bekerja dan mengambil bantuan tugas database dari pakar big data teratas
3.2 Fitur:
penyimpanan fakta yang ditentukan.Blok mengurangi mencari waktu.Fakta sangat tersedia karena blok yang sama adalah hadiah di lebih dari satu simpul fakta.Meskipun banyak simpul fakta turun, kita tetap dapat melakukan lukisan kita, yang membuatnya sangat dapat diandalkan. toleransi kesalahan yang berlebihan.
Kekurangan:
pada saat yang sama karena HDFS memiliki banyak kemampuan, ada beberapa tempat di mana ia gagal.
Data latensi rendah masuk ke program yang memerlukan informasi latensi rendah masuk, termasuk dalam milidetik, juga dapat berperang dengan HDFS, yang dibuat untuk mencapai catatan throughput tinggi pada laju latensi. Kerumitan file kecil: Memiliki berbagai macam file kecil akan menghasilkan berbagai macam pencarian dan banyak gerakan dari satu node data ke node lainnya ke ML di notebook Jypyter mendapatkan setiap catatan kecil; itu adalah fakta yang sangat tidak efisien untuk mendapatkan hak masuk ke pola tersebut.